

Selon une nouvelle étude, les IA génératives donnent encore 30 % de fausses informations lorsqu'on les interroge. Les LLM sont-ils voués à dire n'importe quoi ?

On pourrait espérer que les avancées en matière d’intelligence artificielle contribuent à réduire peu à peu leur principal défaut : leur fâcheuse propension à raconter parfois n’importe quoi avec la plus grande assurance. Mais, malheureusement, il n’en est rien.
C’est ce que montre un nouvel outil de benchmark baptisé Halluhard, développé par un collectif de chercheurs (EPFL, ELLIS Institute de Tübingen et Max Planck Institute for Intelligent Systems).
Des erreurs distillées au mileu de bonnes réponses
La particularité de ce nouvel outil est qu'il ne se contente pas de contrôler les réponses à des questions simples, mais il s'attaque aux conversations longues que l'on peut avoir avec les chatbots. Quatre secteurs critiques sont testés : le droit, la science, la médecine et le code. L'outil extrait les faits clés et les confronte aux sources citées par l’IA. Or, le résultat est sans appel : à un moment ou à un autre, l'IA déraille.
Des différences selon les modèles
Même la meilleure configuration testée, Claude Opus 4.5 avec recherche web activée, produit des hallucinations dans près de 30 % des cas. Sans accès au web, ce taux grimpe autour de 60%. De son côté, GPT-5.2 Thinking avec recherche web affiche un taux de 38,2 %.
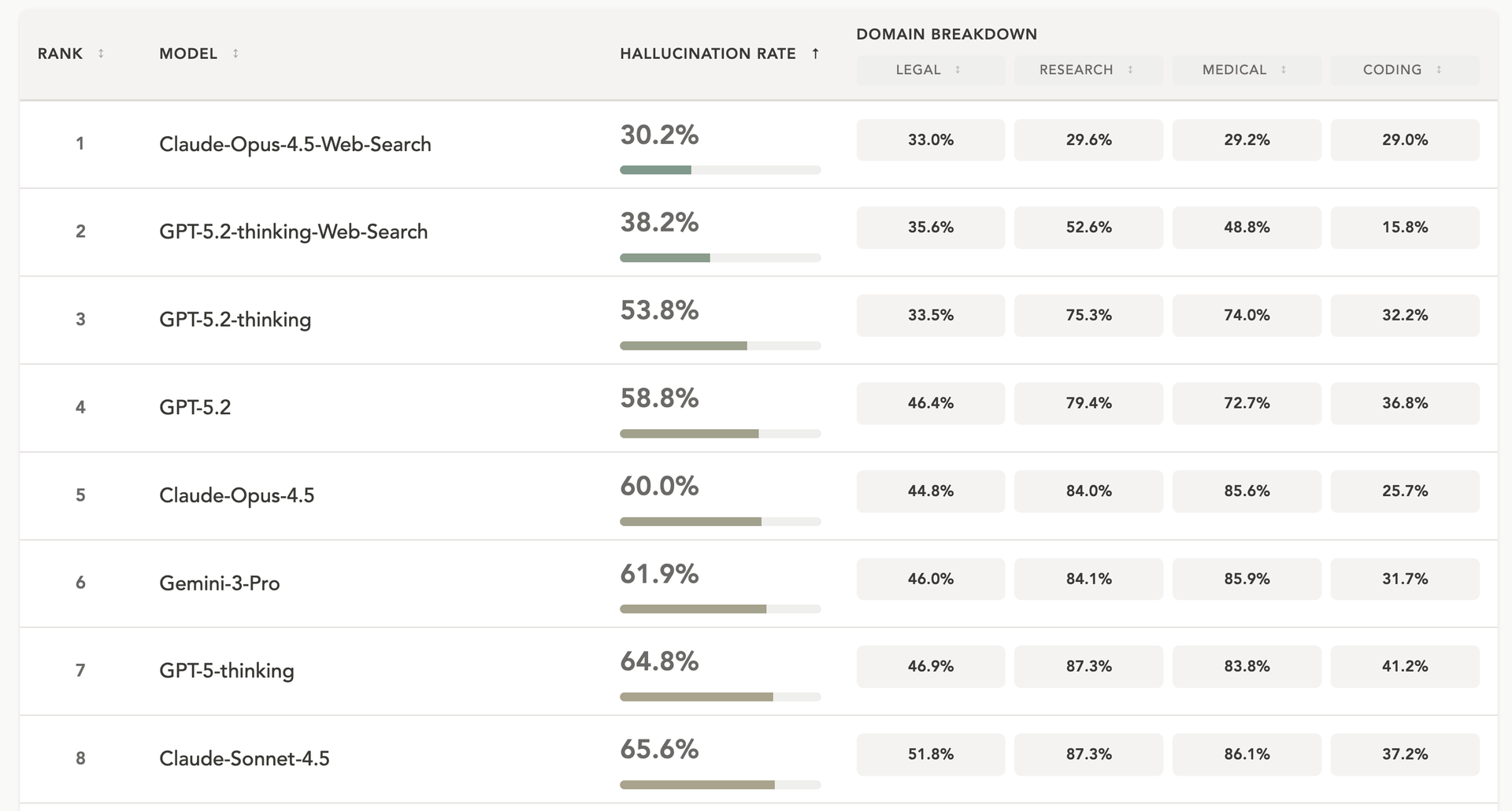
Les grands s'en sortent mieux que les petits
L’étude confirme que les modèles de grande taille hallucinent moins que les plus petits. Les différentes versions d'un même outil d'IA présentent des écarts assez forts. Ainsi, dans la gamme GPT-5, le taux moyen passe de plus de 85 % pour les versions nano à un peu plus de 50 % pour les versions qui intègrent du raisonnement avancé.
Autre observation : les versions avec raisonnement plus profond (Thinking) permettent de réduire partiellement les erreurs. Cependant, il y a un effet paradoxal : les réponses plus longues contiennent davantage d'erreurs car elles comptent davantage d’affirmations.
La prudence reste de mise
Dans ces conditions, comment espérer pouvoir se fier un jour à l'IA dans le secteur juridique ou médical ? Une réponse lisse avec citations risque de contenir des erreurs subtiles, comme un détail médical exagéré ou une loi mal interprétée. L'utilisateur moyen doit donc multiplier les vérifications avant d’agir, surtout pour des infos pointues. La présence de liens ne suffit pas : il faut aller vérifier par soi-même. L’IA excelle à afficher du plausible en citant une source réelle mais sans la respecter.
Une fatalité ?
Cela pourra-t-il s'améliorer un jour ? Probablement pas. La plupart des chercheurs estiment que les hallucinations font partie du fonctionnement même des grands modèles de langage : ils ne vérifient pas la vérité, ils prédisent le texte le plus plausible. Des travaux théoriques concluent même que ces hallucinations sont inévitables et ne peuvent pas être totalement éliminées, quelles que soient l’architecture ou les données d’entraînement.
Cependant, on peut fortement les réduire. Des techniques comme la récupération d’informations en temps réel (RAG), l’apprentissage avec retour humain ou la vérification automatique des faits permettent de diminuer sensiblement les erreurs et d’améliorer la fiabilité des réponses. Malheureusement, les hallucinations seraient inévitables, même avec des données parfaites, selon cette étude de 2025.
Lire aussi : Aux Etats-Unis, premiers procès contre des IA pour hallucinations
Partager cet article sur votre réseau préféré :





